scrapy爬虫框架在业内大大有名,自己写过静态网页和动态网页的爬虫,一直没拿scrapy来写,近来看了scrapy的官方文档,了解了大致的流程,故拿来练手实践了一个项目。
本文主要抓取股吧的文章,内容包括:
- 定义抓取Spider
- 数据字段的定义
- 内容解析
- 数据存储到mysql
- PyCharm调试scrapy
一、定义抓取Spider
创建一个新的Spider
1
2
| scrapy startproject tutorial
scrapy genspider guba_spider eastmoney.com
|
默认创建的Spider是继承与BaseSpider,一般我们继承功能更多的CrawlSpider。
1
2
3
4
5
6
7
| from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class GubaSpider(CrawlSpider):
name = 'guba'
allowed_domains = ['eastmoney.com']
|
定义好GubaSpider类后,然后要指定开始网页start_urls和rules抓取网页规则。
1
2
3
4
5
6
7
8
9
10
| start_urls = [
'http://guba.eastmoney.com/default_%d.html' % index for index in range(1, 100)
]
rules = (
# 提取匹配 文章 的链接并使用spider的parse_article方法进行分析
Rule(LinkExtractor(allow=(r'^http://guba.eastmoney.com/news.', )), callback='parse_article'),
Rule(LinkExtractor(allow=(r'^http://iguba.eastmoney.com/\d+.',)), callback='parse_auther')
)
|
我们主要爬取的是下面这块区域:
rules规则定义了两类链接,一个是文章链接,一个是作者链接。
链接的规则可以通过Chrome的开发者工具得到,如下:
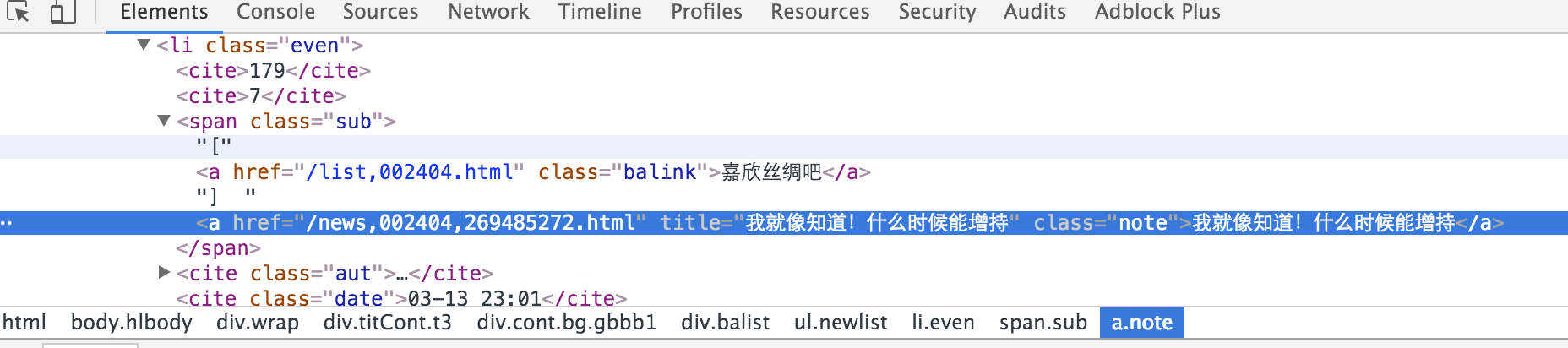
Rule中的LinkExtractor是从网页(scrapy.http.Response)中抽取满足allow条件的链接,callback回调至指定函数。
启动Spider,执行的流程是:
从start_urls中开始爬取网页,
找到满足文章链接的规则,跳转到self.parse_article()函数进一步处理。
二、定义数据字段
在scrapy目录下的items.py中定义结构化数据字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import scrapy
class ArticleItem(scrapy.Item):
uuid = scrapy.Field() # 唯一标识符
user_id = scrapy.Field()
user_name = scrapy.Field()
title = scrapy.Field()
classify = scrapy.Field()
content = scrapy.Field()
readed_count = scrapy.Field()
comment_count = scrapy.Field()
href = scrapy.Field()
source = scrapy.Field()
published_date = scrapy.Field()
scrapy_date = scrapy.Field() # 抓取日期
|
三、内容解析
scrapy默认的是用xpath解析网页,由于对Beautifulsoup更熟悉,我在本文中用的Beautifulsoup来解析网页内容,道理都是一样的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| from bs4 import BeautifulSoup as bs
import re
from hashlib import md5
from gubademo.items import ArticleItem
def parse_article(self, response):
print "content news:%s" % response.url
soup = bs(response.body, 'lxml')
item = ArticleItem()
item['title'] = response.url
item['href'] = response.url
div_name = soup.find('div',{'id':'zwconttbn'})
if div_name:
item['user_name'] = div_name.find('a').text
if div_name.find('a').has_attr('data-popper'):
item['user_id'] = div_name.find('a')['data-popper']
span_stockname = soup.find('span', {'id':'stockname'})
if span_stockname:
item['classify'] = span_stockname.find('a').text
# 内容
c_div = soup.find('div', {'class':'stockcodec'})
if c_div:
item['content'] = ''
for s in c_div.strings:
item['content'] += s
# 时间
t_div = soup.find('div', {'class':'zwfbtime'})
if t_div:
s1 = re.search('\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}',t_div.text)
if s1:
item['published_date'] = s1.group()
# 阅读数和评论数
m = re.search('num=(\d+).*?var count=\d+', response.body)
if m:
item['readed_count'] = m.group(1)
else:
item['readed_count'] = u'0'
m = re.search('var pinglun_num=(\d+)', response.body)
if m:
item['comment_count'] = m.group(1)
else:
item['comment_count'] = u'0'
item['source'] = 'guba_eastmoney'
item['scrapy_date'] = GetNowTime()
item['uuid'] = md5(item['href']).hexdigest()
print item
yield item
|
四、写入数据库
解析完数据,接下来是要保存数据以便以后分析使用。
自定义Pipeline,spider将item传递到pipeline,默认调用的是process_item()函数,我们可以在processs_item中根据item的类型进行差异化处理。
需要先在setting.py中设置如下内容,scrapy才能走着这一步。
1
2
3
4
5
6
| # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'wealth_tech.pipelines.DuplicatePipeline':200,
'wealth_tech.pipelines.MySQLStorePipeline': 300,
}
|
MySQLStorePipeline定义了一个article_items集合用于存储spider爬到的item,当items数量达到1000时,批量写入数据库。如果接受到item就单条写入数据库,会比批量写入慢很对,爬虫的效率会慢一个数量级。
存入mysql之前,先查询数据库,若不存在则insert,存在则update。
数据库的host,port等信息一般存在setting.py中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| import MySQLdb
import MySQLdb.cursors
import pandas as pd
import wealth_tech.settings as settings
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://%s:%s@%s:%d/%s' % (settings.MYSQL_USER, settings.MYSQL_PASSWD, settings.MYSQL_HOST, 3306, settings.MYSQL_DBNAME), connect_args={'charset':'utf8'})
class MySQLStorePipeline(object):
"""
写入mysql数据库
"""
def __init__(self):
self.article_items = {}
# pipeline默认调用
def process_item(self, item, spider):
print spider.name
if type(item) is ArticleItem:
self.process_article_item(item, spider) # 文章
return item
def process_article_item(self, item, spider):
"""
保存文章
"""
table = 'article_guba_easymoney'
self.article_items.setdefault(spider.name, [])
self.article_items[spider.name].append(item)
if len(self.article_items[spider.name]) >= 1000: # 积累到1000条就写入数据库
conn=MySQLdb.connect(host=settings.MYSQL_HOST,user=settings.MYSQL_USER,passwd= settings.MYSQL_PASSWD,db=settings.MYSQL_DBNAME,charset="utf8")
cursor = conn.cursor()
df = pd.read_sql('select uuid from {}'.format(table), engine)
uuids = df['uuid'].get_values()
uuids = set(uuids)
for item in self.article_items[spider.name]:
try:
if item['uuid'] not in uuids:
# 插入
sql = 'insert into {} values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'.format(table)
param = (item['uuid'],item['user_id'],item['user_name'],item['title'],item['classify'],item['content'],
item['readed_count'],item['comment_count'],item['href'],item['source'],item['published_date'],item['scrapy_date'])
n = cursor.execute(sql,param)
print 'insert ',n, item['uuid']
else:
#更新
sql = "update {} set fans_count=%s, article_count=%s,visit_count=%s,comment_count=%s,scrapy_date=%s where user_id='{}'".format(table, item['user_id'])
#print sql
param = (item['fans_count'],item['article_count'],item['visit_count'],item['comment_count'],item['scrapy_date'])
n = cursor.execute(sql,param)
print 'update', n,item['uuid']
except Exception,e:
print e
#提交
conn.commit()
#关闭
conn.close()
self.article_items[spider.name] = []
|
数据库呈现的结果:

五、PyCharm Debug调试scrapy
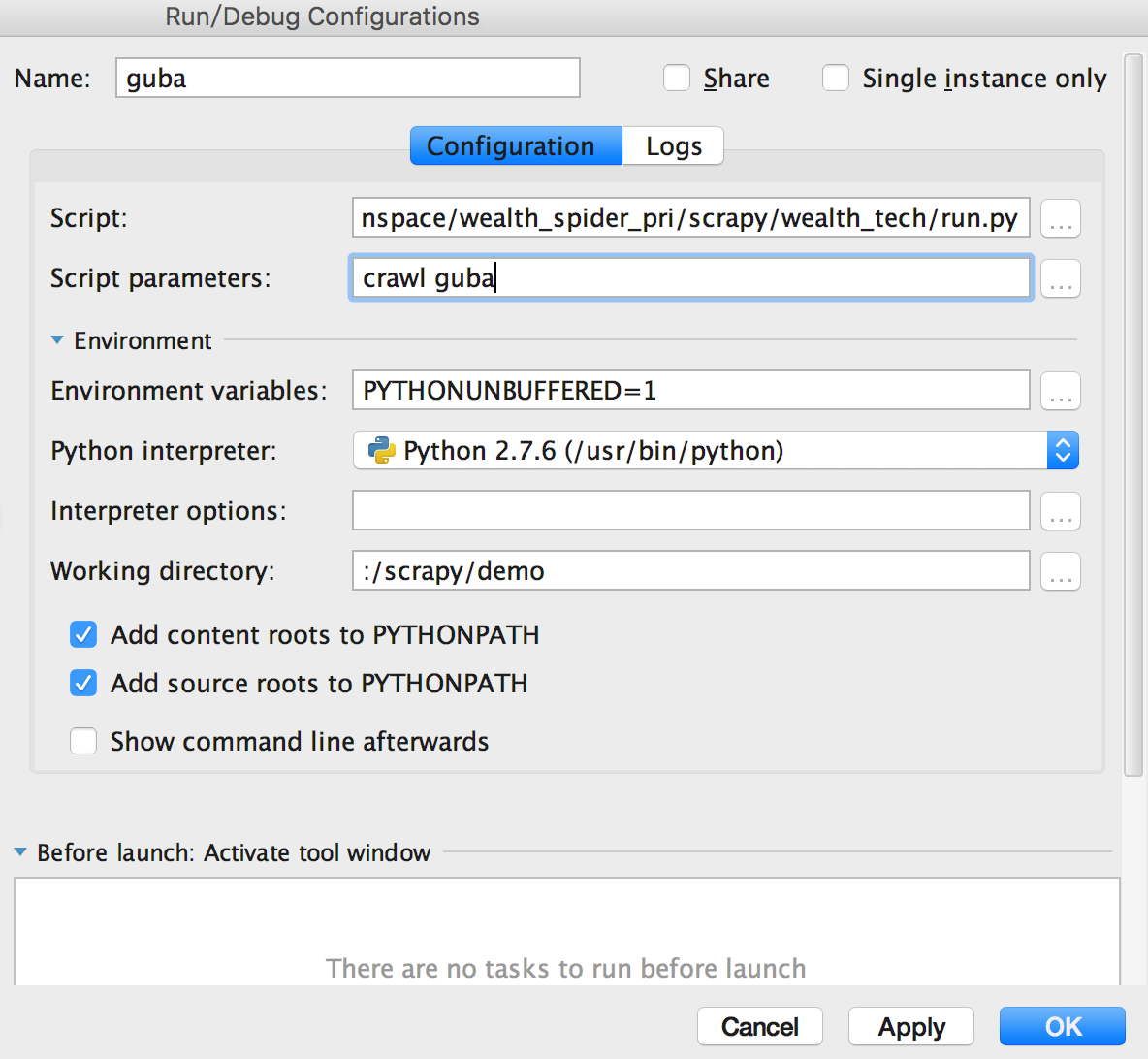
scrapy通常在命令行里运行,但仅通过log显示的信息来调试时非常费劲的,程序猿需要的是单步调试,step by step。
在PyCharm中调试也是很容易的。
在scrapy项目的根目录下(与scrapy.cfg同级)新建一个文件run.py,内容如下:
1
2
3
4
| #!/usr/bin/python
from scrapy.cmdline import execute
execute()
|
新建一个Run/Debug Configurations,Script选择run.py,Script parameters输入crawl guba。其中guba是在GubaSpider中定义的name。这样启动Debug就能单步调试了。