一、什么是ZooKeeper?
ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员,同时Apache HBase、Apache Solr、LinkedIn Sensei等众多项目中都采用了ZooKeeper。
ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员,同时Apache HBase、Apache Solr、LinkedIn Sensei等众多项目中都采用了ZooKeeper。
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库 (计算机)。
从https://github.com/getredash/redash 拉取代码,运行docker-compose.production.yml
主要修改了两处:
1,增加了redis和postgres的db文件与宿主机的映射,不让docker容器停止后数据丢失。
官方默认的docker-compose.production.yml在docker-compose down 命令后,所有的配置信息都丢失了
最近重构一个Scrapy爬虫项目,需要将300个spider的调度任务在jenkins中添加。这已经超过了手动一个一个添加任务的极限,是时候要借助工具批量添加了。
Jenkins提供了一套远端访问的API,目前有3种方式:
XML
JSON with JSONP support
Python
Gunicorn是一个被广泛使用的高性能的Python WSGI UNIX HTTP服务器,移植至Ruby的独角兽(Unicorn)项目,使用pre-fork worker模式,具有使用非常简单,轻量级的资源消耗,以及高性能等特点。
Django自带的简易服务器,它是一个纯Python写的轻量级的WEB服务器,但它是为了开发而设计的,不适合在生产环境中部署。
公司目前用的前后端分离的架构,API接口的稳定性直接影响了与前端团队的沟通效率,前端开发和测试人员都比较熟练的使用Postman来测试API接口。
API接口的自动化测试有很多方案,但Postman+Newman+Jenkins的组合方案,对于测试人员的学习成本最低,实现起来速度是最快的。
由于公司目前已经采用Jenkins做自动化部署,因此只需要安装Newman,整个流程即可走通。
现在运营商提供的宽带服务,无论是动态IP,还是固定IP,默认都是禁止所有端口服务的(目前了解上海是这样的),在路由器上配置的端口映射和DMZ都失效。申请开通端口需要域名备案,过程比较繁琐。
运营商这么做是为了防止个人随意开设各种非法服务,也防止黑客通过扫描器进行抓鸡和批量扫描。这样封禁,虽然一定程度上保证了我们的网络安全,比如说前段时间的勒索病毒正因为国内大部分用户没有独立的公网IP,并且操作系统最容易爆发漏洞的一些,135,139等端口被运营商封禁了,使得国内个人家庭电脑中招的概率小了很多;但是导致即使有公网IP,也无法使用常用端口向外网提供服务。
公司内部网盘分享方案。
目前开源的企业网盘方案有seafile,ownCloud。
Seafile 是一款开源的企业云盘,注重可靠性和性能。支持 Windows, Mac, Linux, iOS, Android 全平台。支持文件同步或者直接挂载到本地访问。
Dockerfile 运行只支持一条命令,当在Docker里要运行多条命令,用supervisor来管理就比较合适了。
Supervisor是一个 Python 开发的 client/server 系统,可以管理和监控类 UNIX 操作系统上面的进程。它可以同时启动,关闭多个进程,使用起来特别的方便。
supervisor 主要由两部分组成:
但是使用supervisor,Django运行的日志就不会在Docker里输出了,默认的输出如下:
1 | 2018-03-28 06:48:20,292 CRIT Supervisor running as root (no user in config file) |
上面的Docker中supervisor配置如下:
1 | [supervisord] |
这样的配置在容器中是同时运行Django,celery。
1 | [inet_http_server] |
实测发现Django的日志输出会写到stderr.log文件中,所以在配置文件中将错误日志重定向到标准日志里;
1 | redirect_stderr=true |
容器中的生成的日志文件如下:
1 | root@a16bc77e96bc:/var/log/supervisor# ls |
运行容器时,将9001端口映射出去,通过ip:9001访问: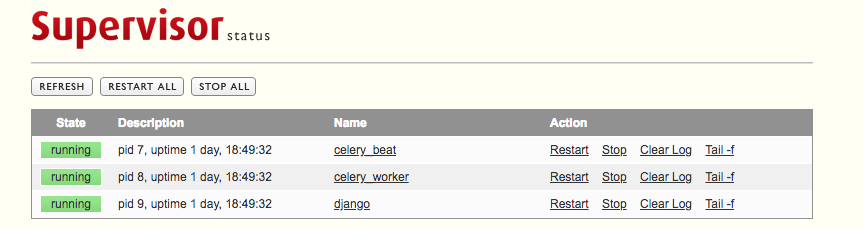
点击 Tail -f 查看各个进程的日志。