技术原理
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库 (计算机)。
Kafka是一个分布式的、高吞吐量、高可扩展性的消息系统。Kafka 基于发布/订阅模式,通过消息解耦,使生产者和消费者异步交互,无需彼此等待。Ckafka 具有数据压缩、同时支持离线和实时数据处理等优点,适用于日志压缩收集、监控数据聚合等场景。
关键名词:
broker:kafka集群包含一个或者多个服务器,服务器就称作broker
producer:负责发布消息到broker
consumer:消费者,从broker获取消息
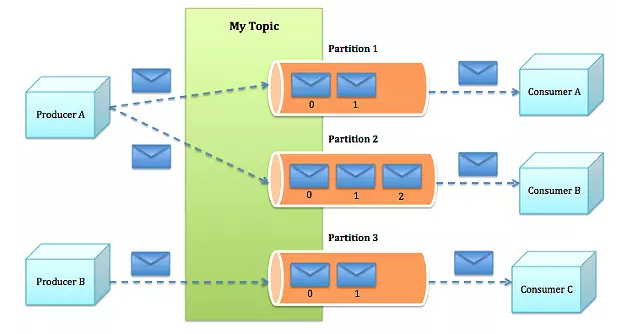
topic:发布到kafka集群的消息类别。
partition:每个topic划分为多个partition。
group:每个partition分为多个group
架构示意图
一个典型的Kafka集群中包含若干Producer(可以是web前端FET,或者是服务器日志等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干ConsumerGroup,以及一个Zookeeper集群。
Kafka通过Zookeeper管理Kafka集群配置:选举Kafka broker的leader,以及在Consumer Group发生变化时进行rebalance,因为consumer消费kafka topic的partition的offsite信息是存在Zookeeper的。
Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。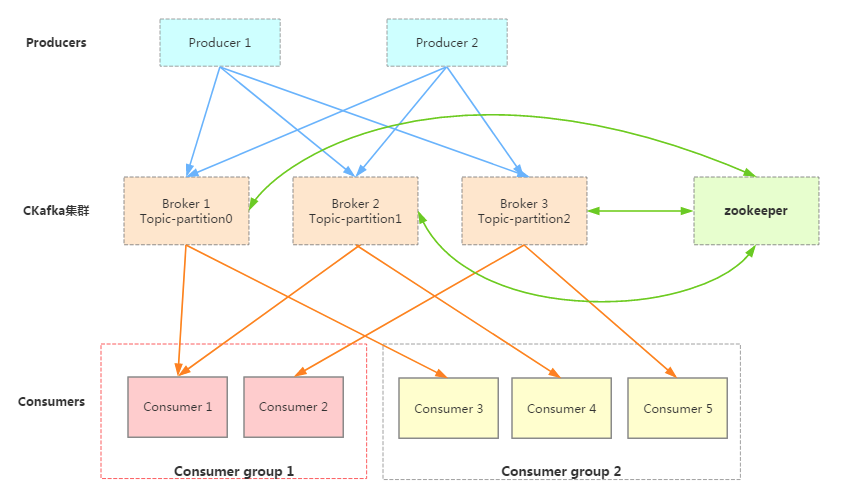
一个典型的Cloud Kafka集群如上所示。其中的生产者Producer可能是网页活动产生的消息、或是服务日志等信息。生产者通过push模式将消息发布到Cloud Kafka的Broker集群,消费者通过pull模式从broker中消费消息。消费者Consumer被划分为若干个Consumer Group,此外,集群通过Zookeeper管理集群配置,进行leader选举,故障容错等。
kafka特点:
- 它是一个处理流式数据的”发布-订阅“消息系统。
- 实时高效处理流式数据:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 将数据安全存储在分布式集群。
- 它是运行在集群上的。
- 它将流式记录存储在topics中。
- 每个record由key, value和timestamp组成。
Docker搭建
参考:https://github.com/wurstmeister/kafka-docker
docker-compose.yml如下:
1 |
|
参数说明:
- KAFKA_ADVERTISED_HOST_NAME:Docker宿主机IP(如果你要配置多个brokers,就不能设置为 localhost 或 127.0.0.1)
- KAFKA_MESSAGE_MAX_BYTES:kafka(message.max.bytes) 会接收单个消息size的最大限制,默认值为1000000 , ≈1M
- KAFKA_CREATE_TOPICS:初始创建的topics,可以不设置
- 环境变量./kafka-logs为防止容器销毁时消息数据丢失。
- 容器kafka-manager为yahoo出可视化kafka WEB管理平台。
操作命令:
1 |
|
Kakfa使用
1,Kafka管理节点
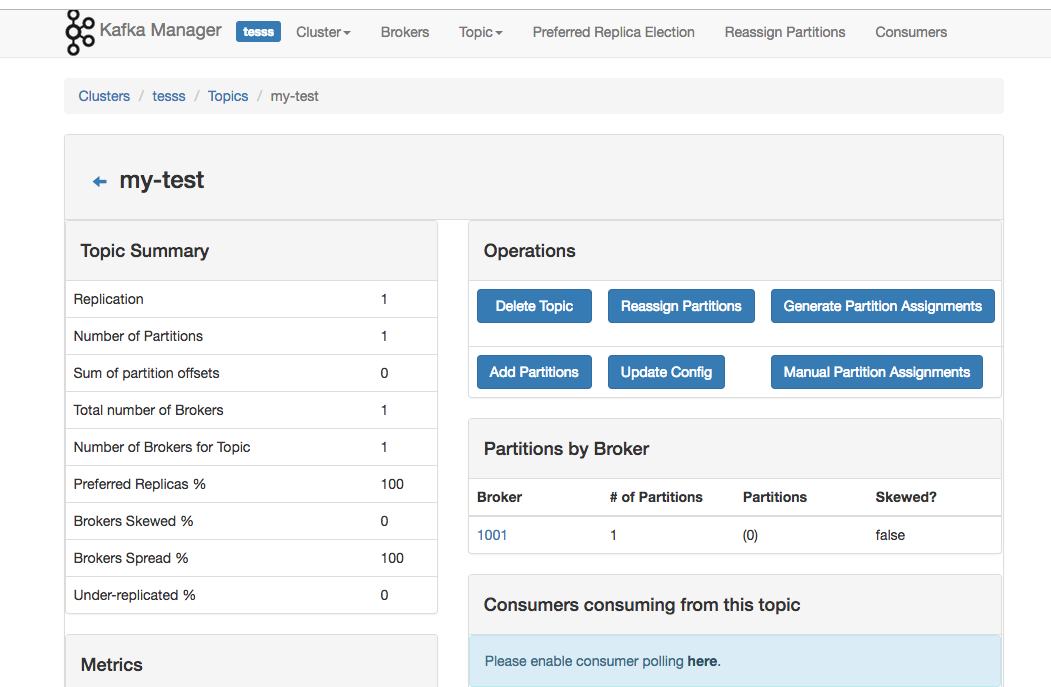
2,主题
1 | environment: |
Topic1有1个Partition和3个replicas, Topic2有2个Partition,1个replica和cleanup.policy为compact。
Topic 1 will have 1 partition and 3 replicas, Topic 2 will have 1 partition, 1 replica and a cleanup.policy set to compact.
3,读写验证
读写验证的方法有很多,这里我们用kafka容器自带的工具来验证,首先进入到kafka容器的交互模式:
1 | docker exec -it kafka_kafka_1 /bin/bash |
创建一个主题:
1 | /opt/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.31.84:2181 --replication-factor 1 --partitions 1 --topic my-test |
查看刚创建的主题:
1 | /opt/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.31.84:2181 |

发送消息:
1 | /opt/kafka/bin/kafka-console-producer.sh --broker-list 192.168.31.84:9092 --topic my-test |
读取消息:
1 | /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.31.84:9092 --topic my-test --from-beginning |
使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
参考:
1,https://www.jianshu.com/p/bfeceb3548ad
2,https://www.jianshu.com/p/7f089cdff29a
3,https://www.cnblogs.com/iforever/p/9130983.html
4,利用flume+kafka+storm+mysql构建大数据实时系统
5,Kafka系列(四)Kafka消费者:从Kafka中读取数据
6,基于Docker搭建分布式消息队列Kafka