scrapy爬虫写好后,需要用命令行运行,如果能在网页上操作就比较方便。scrapyd部署就是为了解决这个问题,能够在网页端查看正在执行的任务,也能新建爬虫任务,和终止爬虫任务,功能比较强大。
一、安装
1,安装scrapyd
1 | pip install scrapyd |
2, 安装 scrapyd-deploy
1 | pip install scrapyd-client |
windows系统,在c:\python27\Scripts下生成的是scrapyd-deploy,无法直接在命令行里运行scrapd-deploy。
解决办法:
在c:\python27\Scripts下新建一个scrapyd-deploy.bat,文件内容如下:
1 | @echo off |
添加环境变量:C:\Python27\Scripts;
二、使用
1,运行scrapyd
首先切换命令行路径到Scrapy项目的根目录下,
要执行以下的命令,需要先在命令行里执行scrapyd,将scrapyd运行起来
1 | MacBook-Pro:~ usera$ scrapyd |
2,发布工程到scrapyd
a,配置scrapy.cfg
在scrapy.cfg中,取消#url = http://localhost:6800/前面的“#”,具体如下:,
然后在命令行中切换命令至scrapy工程根目录,运行命令:
1 | scrapyd-deploy <target> -p <project> |
示例:
1 | scrapd-deploy -p MySpider |
- 验证是否发布成功
1 | scrapyd-deploy -l |
一,开始使用
1,先启动 scrapyd,在命令行中执行:
1 | MyMacBook-Pro:MySpiderProject user$ scrapyd |
2,创建爬虫任务
1 | curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2 |
- bug:
scrapyd deploy shows 0 spiders by scrapyd-client
scrapy中有的spider不出现,显示只有0个spiders。 - 解决
需要注释掉settings中的When setting LOG_STDOUT=True, scrapyd-deploy will return ‘spiders: 0’. Because the output will be redirected to the file when execute ‘scrapy list’, like this: INFO:stdout:spider-name. Soget_spider_list can not parse it correctly.1
2
3
4# LOG_LEVEL = "ERROR"
# LOG_STDOUT = True
# LOG_FILE = "/tmp/spider.log"
# LOG_FORMAT = "%(asctime)s [%(name)s] %(levelname)s: %(message)s"
3,查看爬虫任务
在网页中输入:http://localhost:6800/
下图为http://localhost:6800/jobs的内容: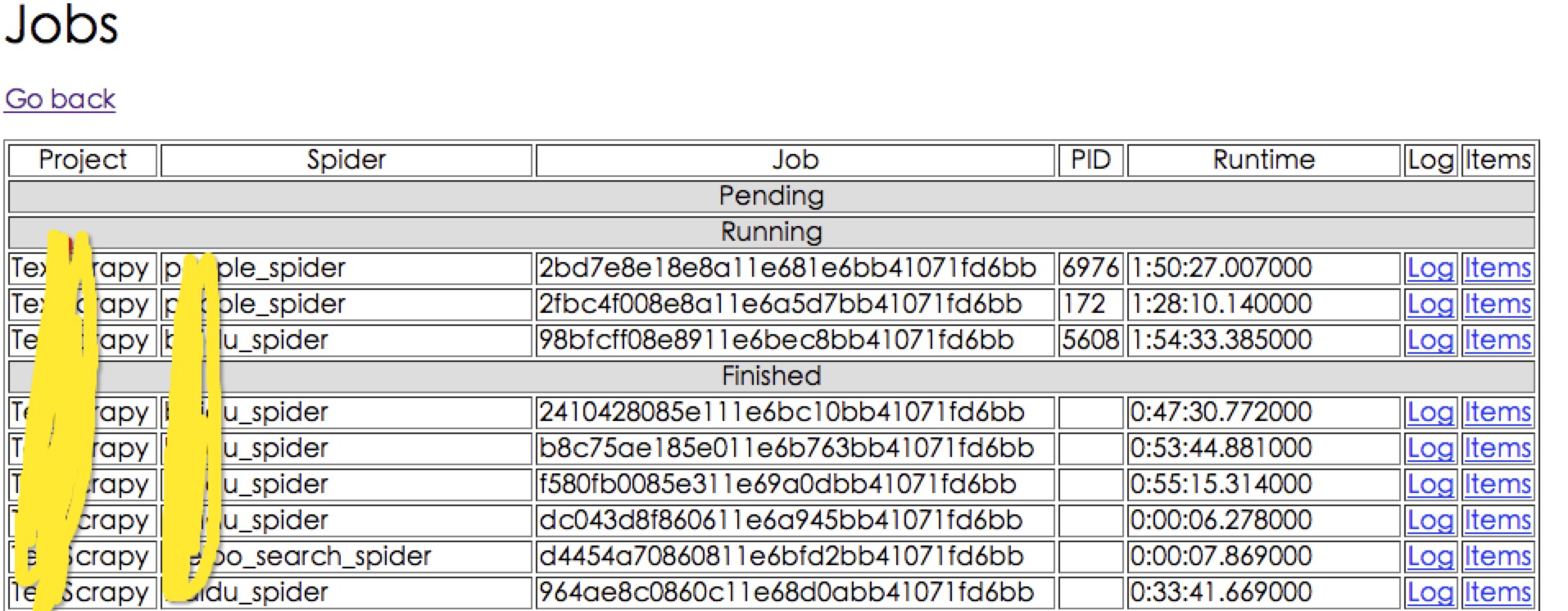
4,运行配置
配置文件:C:\Python27\Lib\site-packages\scrapyd-1.1.0-py2.7.egg\scrapyd\default_scrapyd.conf
1 | [scrapyd] |
参考
http://www.cnblogs.com/jinhaolin/p/5033733.html
https://scrapyd.readthedocs.io/en/latest/api.html#cancel-json