概念
朴素贝叶斯算法是一个直观的方法,使用每个属性属于某个类的概率来做预测。你可以使用这种监督性学习方法,对一个预测性建模问题进行概率建模。
给定一个类,朴素贝叶斯假设每个属性归属于此类的概率独立于其余所有属性,从而简化了概率的计算。这种强假定产生了一个快速、有效的方法。
给定一个属性值,其属于某个类的概率叫做条件概率。对于一个给定的类值,将每个属性的条件概率相乘,便得到一个数据样本属于某个类的概率。
1、贝叶斯定理
假设对于某个数据集,随机变量C表示样本为C类的概率,F1表示测试样本某特征出现的概率,套用基本贝叶斯公式,则如下所示:
%20=%20\dfrac{P(CF_{1})}%20{P(F_{1})}%20=%20\dfrac{P(C)*P(F_{1}|C)}{P(F_{1})})
上式表示对于某个样本,特征F1出现时,该样本被分为C类的条件概率。
对该公式,有几个概念需要熟知:
*先验概率(Prior) *。P(C)是C的先验概率,可以从已有的训练集中计算分为C类的样本占所有样本的比重得出。
证据(Evidence)。即上式P(F1),表示对于某测试样本,特征F1出现的概率。同样可以从训练集中F1特征对应样本所占总样本的比例得出。
似然(likelihood)。即上式P(F1 | C),表示如果知道一个样本分为C类,那么他的特征为F1的概率是多少。
对于多个特征而言,贝叶斯公式可以扩展如下:
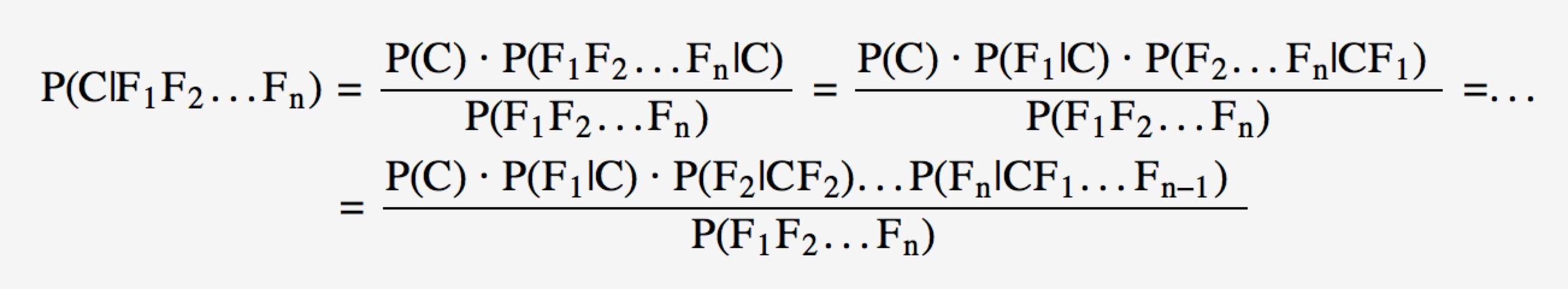
分子中存在一大串似然值。当特征很多的时候,这些似然值的计算是极其痛苦的。
2、朴素的概念
为了简化计算,朴素贝叶斯算法假设:“朴素的认为各个特征相互独立”。这样一来,上式的分子就简化成了:
*P(F_{1}|C)*P(F_{2}|C)...P(F_{n}|C) )
这个假设是认为各个特征之间是独立的,看上去确实是个很不科学的假设。因为很多情况下,各个特征之间是紧密联系的。然而在朴素贝叶斯的大量应用实践表明其工作的相当好。
其次,由于朴素贝叶斯的工作原理是计算<img src=”http://www.forkosh.com/mathtex.cgi? P(C=0|F_{1}…F_{n})”和<img src=”http://www.forkosh.com/mathtex.cgi? P(C=1|F_{1}…F_{n})”,并取最大值的那个作为其分类。而二者的分母是一模一样的。因此,我们又可以省略分母计算,从而进一步简化计算过程。
另外,贝叶斯公式推导能够成立有个重要前期,就是各个证据(evidence)不能为0。也即对于任意特征Fx,P(Fx)不能为0。而显示某些特征未出现在测试集中的情况是可以发生的。因此实现上通常要做一些小的处理,例如把所有计数进行+1(加法平滑(additive smoothing,又叫拉普拉斯平滑(Laplace smothing))。而通过增大一个大于0的可调参数alpha进行平滑,就叫Lidstone平滑。
朴素贝叶斯分类器的Python实现
1,定义特征提取器
1
2
3
4
5
6
7
8
|
In[21]: def gender_features(word):
... return {'last_letter':word[-1]}
In[22]: gender_features('Shrek')
Out[22]: {'last_letter': 'k'}
|
函数返回的字典被成为特征集,能把特征名称映射到它们的值。
特征名称提供一个简短的、可读的特征描述;特征值是简单类型的值,如布尔、数字和字符串。
2,准备数据
1
2
3
4
5
6
7
8
|
In[24]: from nltk.corpus import names
In[25]: import random
In[26]: names = ([(name, 'male') for name in names.words('male.txt')] + [(name, 'female') for name in names.words('female.txt')])
In[44]: random.shuffle(names) #元素顺序打乱
|
3,朴素贝叶斯分类器
将特征集的结果链表划分为训练集和测试集。训练集用于训练新的“朴素贝叶斯”分类器。
1
2
3
4
5
6
7
8
9
| In[32]: featuresets = [(gender_features(n), g) for (n, g) in names]
In[33]: train_set, test_set = featuresets[500:], featuresets[:500]
In[34]: classifier = nltk.NaiveBayesClassifier.train(train_set)
In[35]: classifier.classify(gender_features('Neo'))
Out[35]: 'male'
|
4,评估分类器
准确度:
1
2
3
4
|
In[39]: print nltk.classify.accuracy(classifier, test_set)
0.602
|
检查分类器,确定哪些特征对于区分名字的性别是最有效的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
In[43]: classifier.show_most_informative_features(5)
Most Informative Features
last_letter = u'a' female : male = 36.8 : 1.0
last_letter = u'k' male : female = 35.3 : 1.0
last_letter = u'f' male : female = 17.0 : 1.0
last_letter = u'p' male : female = 14.0 : 1.0
last_letter = u'v' male : female = 12.5 : 1.0
|
以a结尾的女性是男性的36倍,这些比率成为似然比。
5,优化
在处理大型语料库时,构建包含所有实例特征的单独链表会占用大量内存。可以使用函数 nltk.classify.apply_features, 类似生成器原理。
1
2
3
4
5
6
7
8
9
10
|
In[46]: from nltk.classify import apply_features
In[47]: train_set = apply_features(gender_features, names[500:])
In[48]: test_set = apply_features(gender_features, names[:500])
In[49]: type(train_set)
Out[49]: nltk.util.LazyMap
|
6,结果评估与改进
将数据分为训练集、开发测试集和测试集。
训练集用于训练模型,开发测试集用于执行错误分析,测试集用于系统的最终评估。
1
2
3
4
5
6
7
8
9
10
11
|
train_names = names[1500:]
devtest_names = names[500:1500]
test_names = names[:500]
train_set = [(gender_features(n), g) for (n, g) in train_names]
devtest_set = [(gender_features(n), g) for (n, g) in devtest_names]
test_set = [(gender_features(n), g) for (n, g) in test_names]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print nltk.classify.accuracy(classifier, devtest_set)
Out: 0.794
|
使用开发测试集生成分类器在预测名字性别时出现的错误列表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
errors = []
for (name, tag) in devtest_names:
guess = classifier.classify(gender_features(name))
if guess != tag:
errors.append((tag, guess, name))
for (tag, guess, name) in sorted(errors):
print 'correct=%-8s guess=%-8s name=%-30s' % (tag, guess, name)
---------------------------------------
Output:
correct=female guess=male name=Adelind
correct=female guess=male name=Alex
correct=female guess=male name=Alyss
correct=female guess=male name=Amber
correct=female guess=male name=Austin
correct=female guess=male name=Averil
correct=female guess=male name=Beatrix
...
|
根据上面的错误列表改进特征提取器,比如发现yn结尾的名字大多以女性为主,但以n结尾的名字往往是男性,因此调整特征提取器使其包含两个字母后缀的特征:
1
2
3
4
5
6
7
8
9
10
|
def gender_features(word):
return {'suffix1':word[-1:],
'suffix2':word[-2:]}
...
print nltk.classify.accuracy(classifier, devtest_set)
Out[]: 0.784
|
参考
http://blog.csdn.net/lsldd/article/details/41542107
[书]Python自然语言处理 Steven Bird, Ewan Klein & Edward Loper